플랫 파일 데이터베이스

자기테이프나 디스크 같은 물리적 저장 공간 속 ‘데이터 블록’에 데이터를 기록하는 방식. 테이프의 특정 위치부터 순차적으로 블록을 읽는 간단한 방식으로 동작한다. 한 데이터 블록에 하나의 데이터만 담는 것이 아니라 여러개의 데이터도 담을 수 있다.
[예시 1]
- 이름 뒤에 전화번호를 붙여서 전화번호부 구축.
- 한 칸의 데이터 블록 사이즈는 400.
- 전화번호 사이즈 20
- 이름 사이즈 10
한 명의 정보를 저장하는데 총 30의 사이즈(이름 10 + 전화번호 20)가 필요하다.
하나의 데이터 블록에는 총 13개의 전화번호 정보를 저장할 수 있다.
장점
- 새로운 전화번호를 추가할 때 테이프 맨 뒤에 추가하면 된다. (간편, 효율)
- 전체 목록을 읽어올 때 테이프의 맨 처음부터 맨 끝까지 차례대로 읽으면 된다. (간편)
한계점
- 특정 조건으로 데이터를 읽을 때 복잡하다. 가나다 순으로 정렬을 할 경우 처음부터 끝까지 순차적으로 읽은 뒤에 메모리 상에서 다시 직접 정렬을 해줘야한다.
- 파일 기반의 데이터 관리 시스템은 중복 데이터 발생 위험이 있다. 치킨집의 전화번호를 직원 B가 등록했지만, 해당 내용을 전달 받지 못한 직원 A가 치킨집의 전화번호를 다시 한번 더 추가할 수 있다.
- 데이터 저장 규칙이 변경되면 프로그램도 변경되어야 한다. [예시 1] 에서 이름의 사이즈가 12로 증가한다면, 1~10까지 이름을 읽도록 작성된 프로그램이 1~12까지 읽도록 변경되어야 한다.
- 특정 정보를 비공개로 두고 싶은 경우 파일을 두개로 나눠야 한다. [예시 1] 에서 전화번호 없이 이름만 있는 데이터 파일이 필요한 경우 전화번호와 이름이 함께 있는 데이터 파일과 이름만 있는 데이터 파일 2가지로 나눠야 한다. 이때 신규 정보 등록이나 기존 정보 제거가 필요한 경우 2개 파일 모두 대응해야 돼서 관리가 어렵다.
계층형 데이터베이스
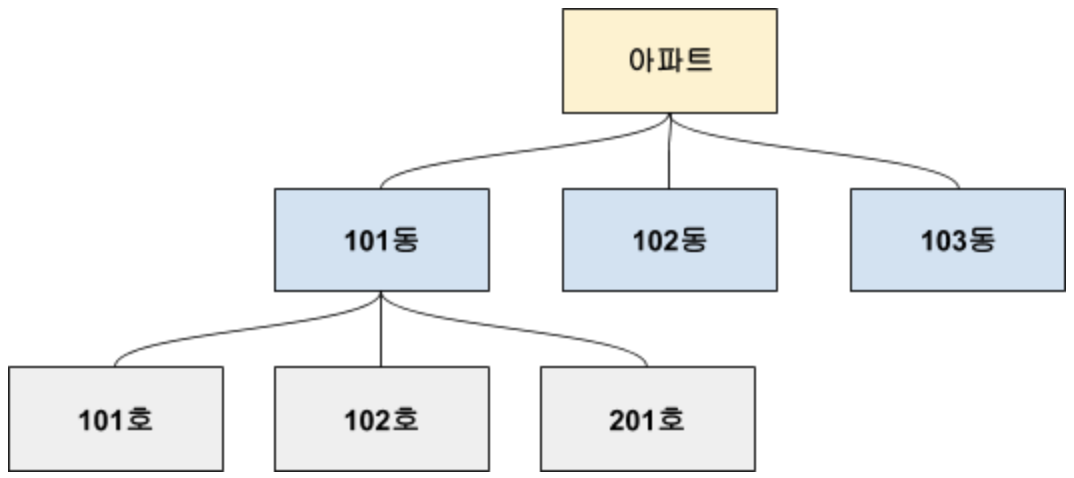
부모-자식 관계의 계층형 구조로 플랫 파일 데이터베이스의 낮은 검색 능력 문제를 해결한다. 계층형 데이터베이스에서 101동에 전체 호수를 검색하기 위해서는 101동의 하위 계층만 확인하면 된다. (102동, 103동의 하위 목록은 확인할 필요가 없음.)

하지만, 플랫 파일 데이터베이스에서는 101동에 사는 전체 호수를 검색하기 위해 테이프의 처음부터 끝까지 읽어야한다. (201호가 테이프 맨 뒤에 있을 수도 있기 때문)
장점
- 특정 조건의 데이터를 검색할 때 전체 데이터를 확인할 필요가 없어서 검색 효율이 높다.
한계점
- 계층형 데이터베이스는 하나의 부모만을 가질 수 있다. 두개 부모의 공통으로 소속된 정보를 표현하려는 경우 똑같은 데이터를 복제하여 유지하여야 한다. 데이터 변경이 생길 때마다 두개 모두 수정이 필요하여 관리가 불편하다.
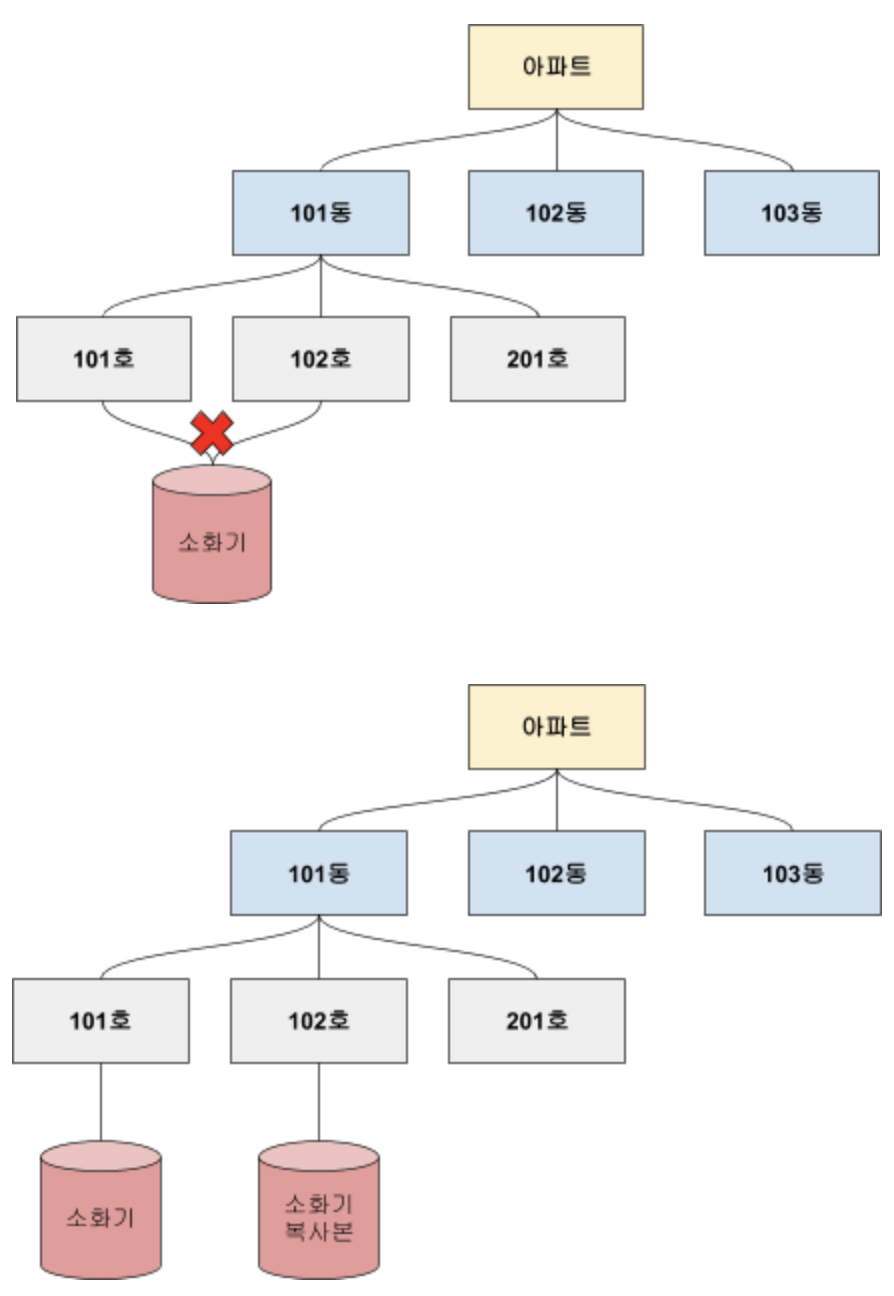
- 데이터 집계시 중복 데이터를 고려하여 집계해야 한다. 예를 들어 101동 1층의 소화기 수를 집계할 때 실제 소화기 수는 1개이지만, 데이터베이스는 복사본이 존재하기 때문에 2개로 집계되는 오류가 생긴다.
네트워크 데이터베이스
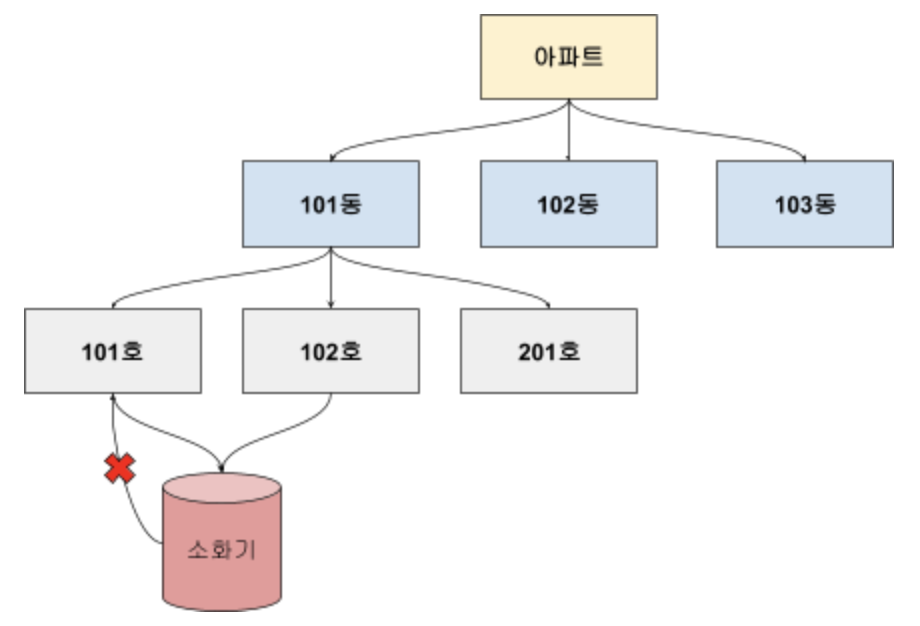
계층형 데이터베이스와 비슷하지만, 복수의 부모를 가질 수 있다. 네트워크 데이터베이스는 방향성으로 부모 자식 관계를 표현한다. 하나의 노드에서 출발하여 이어지는 방향으로 순차적으로 데이터를 접근할 수 있다.
단, 단방향으로 접근이 가능하기 때문에 역행하여 접근하는 것은 불가능하다.
장점
- 복수의 부모와 자식을 가질 수 있기 때문에 계층형 데이터베이스처럼 소화기를 복제하여 가질 필요가 없다.
한계점
- 설계와 관리가 복잡하다.
- 순차적으로 이어진 링크를 따라서 데이터에 접근하기 때문에 설계에 따라서 필요한 데이터까지 접근하는 과정이 길어질 수 있다.
- 모델의 구조가 복잡해지면 링크의 개수와 깊이도 크게 증가한다.